Introduction to Apache Kafka for Python Developers
Introduction
In this blog post, I'll attempt to condense the knowledge I gained from reading the O'Reilly's book "Kafka: The Definitive Guide". We'll introduce Apache Kafka, explain why it’s useful, and present its core concepts. Afterwards, we will dive into a Python application that demonstrates some of these features. By the end of this post, you’ll have a solid high-level understanding of Kafka, learned to start a local Kafka cluster, publish and subscribe messages via the confluent-kafka-python library.
What is Kafka?
Apache Kafka is a distributed streaming platform designed to handle real-time data feeds with high throughput, scalability, and fault tolerance. At its core, Kafka is a publish-subscribe messaging system that allows applications to send (publish) and receive (subscribe to) messages in real time.
Kafka was originally developed at LinkedIn to solve the problem of processing massive amounts of real-time data. Their legacy systems relied on batch processing and polling mechanisms, which were slow, inefficient, and prone to missing updates. Kafka was designed to address these challenges by providing a real-time, pull-based messaging system that could scale horizontally and retain data for extended periods.
Today, Kafka is used by thousands of companies, including Netflix, Uber, and Airbnb, to power their real-time data pipelines and event-driven architectures.
Why use Kafka?
Kafka is widely used in modern applications for its scalability, fault tolerance, and real-time capabilities. As a Python developer, you can use Kafka to:
- Build real-time data pipelines for analytics or machine learning.
- Decouple microservices by enabling asynchronous communication.
- Process high-volume data streams (e.g., logs, metrics, or events).
Python’s rich ecosystem and Kafka’s Python libraries make it easy to integrate Kafka into your applications.
Kafka Architecture Overview
Here’s a high-level overview of how Kafka works:
- Producers publish messages to topics.
- Optional message key determines the destination partition.
- A hash function and modulo in combination with the key.
selected_partition = hash(key) % #partitions
- If no key is specified, round-robin strategy is used to distributed load.
- Topics are divided into partitions, which are distributed across brokers.
- Consumers subscribe to topics and read messages from partitions.
- Messages from a partition are read in the same order as published (first-in first-out).
- Consumer can manually select partitions, which ensures that only specific messages are received.
- Messages are retained for a configurable period, allowing consumers to replay data if needed.
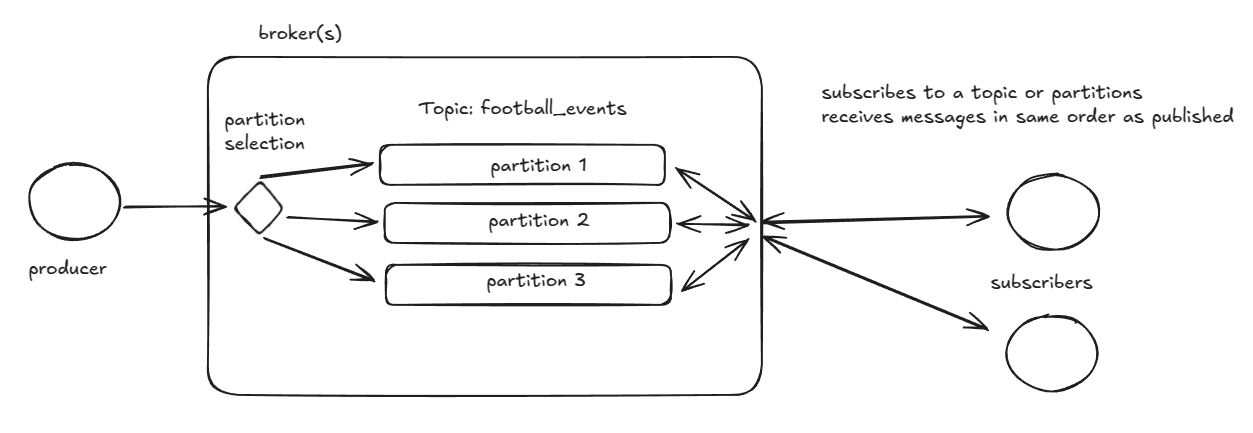
Example: Football Matches
While reading this, keep an eye on the diagram above.
Assume a consumer service that processes all live football match data, like goals, fouls, free kicks and so on. Consumer wishes to propagate this information to the back-end services. Consumer crafts a message that could look like these:
{ "id": "bundesliga", "timestamp": 1741850999, "type": "goal", "team": "FC Bayern Munich" } { "id": "serie-a", "timestamp": 1741850991, "type": "foul", "team": "AC Milan" }
Messages are assigned and publish to partitions based on the key.
For example: hash("bundesliga") % 3 = partition 1 and hash(serie-a) % 3 = partition 3
Subscribers could be services responsible for serving web or mobile users, storing events into databases, computing statistics, sending notifications and so on. Since they subscribed to the topic football_events, a connection is made to each partition, from which they receive messages, A subscriber might only be interested in some specific league, so they could manually subscribe to those partitions. It's important that all events from a single match always go to the same partition, otherwise, the order of messages is not guaranteed. For example, one partition might have signaled that the match is over, while the other, because of congestion, could still send events about the match.
Partitions and replication
In the above example and diagram, we glossed over the parts that make Kafka scalable and durable. A common method to create a fault-tolent system is by replication. Kafka lets you specify the replication factor (configureable via replication.factor), which determines how many replicas of each partition should exist. One partition will always be the leader replica, while others, the follower replicas. All produce and consume requests go through the leader replica. The followers only replicate the data on the leader's partition, and in case that the leader replica crashes or goes offline, one of them will step in as the new leader.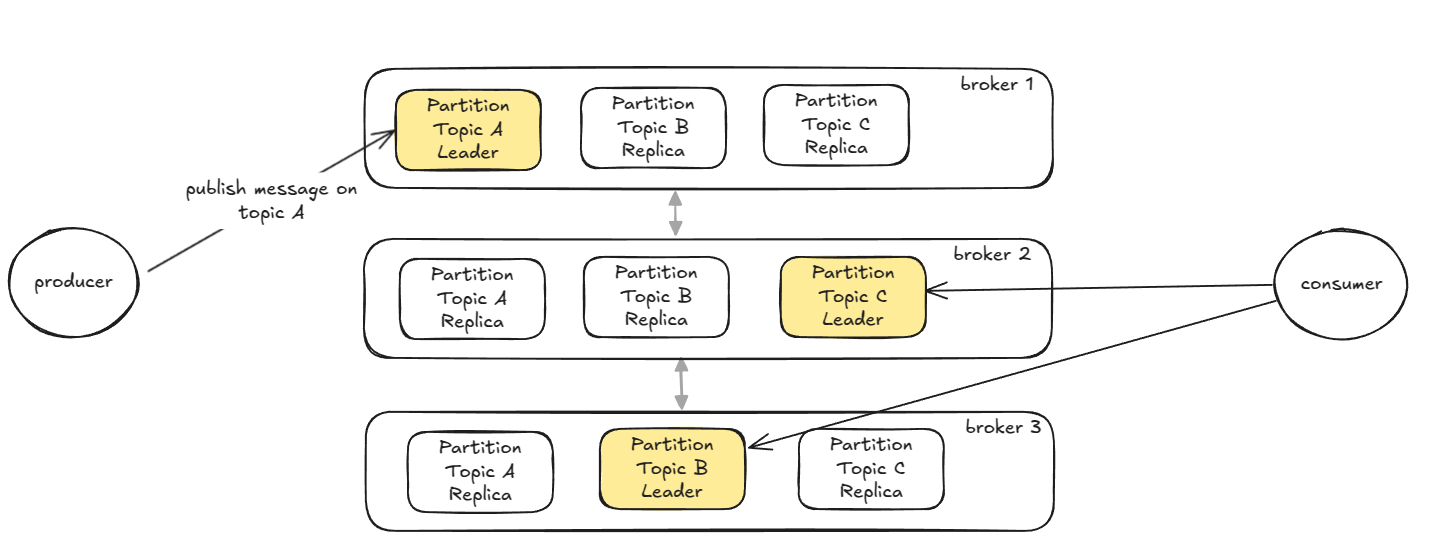
Producers and Consumers
We said before that producers publish messages to topics, more specifically, on partitions. A topic consists of one or more partitions, where each partition is a kind of a serial queue. When a consumer subscribes to a topic, a connection is made to all brokers hosting that topic's partitions. This division enables the parallel consumption of multiple messages by consumers (from each partition). However, there is a potential pitfall if messages that are supposed to be consumed in a serial order, are consumed in parallel order, due to the partition assignment. Producers can specify the partition key, which determine the partition on which the message will be published on. The exact partition key depends on the use-case and must be chosen carefully. Producers can be configured for different behaviour with parameters.
Some notable producer parameters include:
retries: the number of times to try resending a messagebatch.size: the size of the messagecompression.type: compression algorithm (snappy, gzip, lz4)acks: the number of acknowledgements from brokers required to consider the message successfully sent (by commiting the consumer index)
Consumers subscribe to topics and receive messages. Periodically they commit the current message offset (of some partition queue) to kafka on a special internal topic called __consumer_offsets, which gives them durability, such as in case of failure. Furthermore, consumers can be part of consumer groups. Consumer group subscribe to topics and assign partitions to consumer within the group in a 1:1 manner. This means that every message will be consumed only by a single consumer. This is how parallelization is done on the consumer side.
There are two notable parameters for consumer, namely: fetch.min.bytes and fetch.max.wait.ms that define the minimum data received and maximum waiting time before the messages can be consumed via the poll method. Usually, increasing these values will yield higher throughput at the cost of latency.
Lastly, the choice of the partition key particular important, as it defines how the data is distributed across the partitions and the order in which it is consumed. There are no sequential ordering guarantees across partitions. This means that special care must be taken while updating a shared state such as a database, to avoid losing changes or corrupting the state.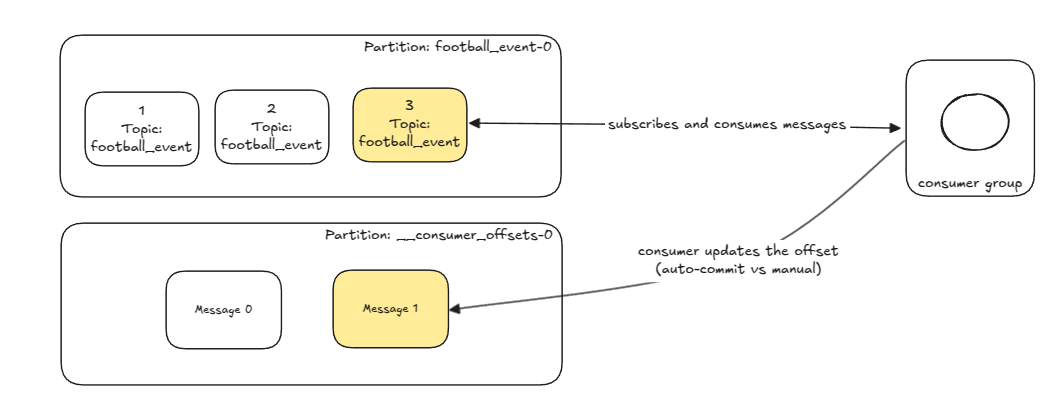
Synchronous example
This section will provide a minimal example of the library confluent-kafka-python usage. The Github page provides many examples for building sync or async consumers and producers, serialization with JSON or AVRO and other. I also put the examples below on my Github page here.
Setup services
We'll need the following services:
- Zookeeper
- A fault-tolerant and highly available key-value store
- Stores meta-data like broker and topic information and consumer offset indexes.
- Kafka Cluster
- Kafka UI
We'll use docker compose to quickly setup the needed services.
file: docker-compose.yml
version: "3"
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.8.0
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ports:
- "2181:2181"
# to survive the container restart
tmpfs: "/zktmp"
kafka:
image: confluentinc/cp-kafka:7.8.0
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka:9092,EXTERNAL://localhost:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_AUTO_CREATE_TOPICS_ENABLE: true # not recommended for production
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9092:9092"
- "29092:29092"
volumes:
- kafka_data:/data/kafka
kafka-ui:
image: provectuslabs/kafka-ui:latest
depends_on:
- kafka
ports:
- "8080:8080"
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9092
KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
volumes:
kafka_data:
driver: local
Start the Docker Compose setup:
Open your browser and navigate to http://localhost:8081.
You’ll see the Kafka UI dashboard, where you can:
- View all Kafka topics.
- Inspect partitions and their offsets.
- Monitor consumer groups.
- Explore messages in real time.
Producer
We will use the confluent_kafka library. Let's start off with defining the external listener of the kafka broker. Then we define a callback function that trigger upon successful message delivery. Finally, we declare a forever loop, in which we send a message to the test_topic topic, setting a key and a value. Flush function will make sure all messages are sent and the callback is called.
=
=
return
=
Consumer
The consumer has slightly more configuration, in which group.id defines the consumer group ID and auto.offset.reset defines the starting point for message consumption. Afterward, it subscribes to the test_topic topic and enter a similar endless loop. During the loop, it will use the poll() function to check for any new messages and perform some checks.
=
=
=
continue
continue
=
# Simulate payment processing...done.
=
Asynchronous example
If we are using asyncio, the synchronous poll and flush methods will block the main thread and make our program run less efficiently. Let's offload those functions to another thread and abstract the produce method to return immediately with a future.
Async Producer
I dropped a few comments in the code about the most important parts. Here is a short summary:
pollmethod of producer blocks, so it needs to run in a dedicated thread.- our produce method must return a future object, so it can be "awaited".
- use
delivery_reportto assign a value to the future defined - use
call_soon_threadsafeto schedule a task on main thread, sincedelivery_reportruns in the same thread aspoll.
= or
=
= False
# start the polling method in a separate thread
=
# this runs in a dedicated thread, so it won't block the main loop
= True
# create a future that we can track the future result and return it
=
# gets triggered upon completion of produce method
# set the result or exception on the future above
# this runs in the same thread as _poll_loop and poll
# call_soon_threadsafe is needed to safely schedule on main thread
return
return
=
=
=
await
=
await
Async Consumer
The examples page does not show an example of a consumer, but we can apply a similar idea to the consumer. Let's summarize again the main ideas:
- use a dedicated thread to poll the consumer and add items to the queue
- provide a async and async iterator pattern to fetch messages from the queue
=
= False
# start the polling method in a separate thread
=
# a queue that holds the incoming messages
=
= True
# this runs in a dedicated thread
# poll for new messages
=
continue
continue
# append the message to queue
# append is atomic
# async iterator
return
# async iterator's next method returns items from the queue
=
return
# queue is empty, try again later
await
# synchronous method
return
return None
=
=
=
# Simulate payment processing
=
Conclusion
In this post, we’ve explored Apache Kafka’s core architecture—brokers, topics, producers, and consumers—and put theory into practice with a Python example simulating real-time banking transactions. While simple, this foundation unlocks Kafka’s potential for fintech use cases like fraud detection, event-driven microservices, and compliance logging, where low latency and data reliability are critical.
Serialization remains a key topic we didn’t dive into deeply. Kafka supports structured message schemas (like Avro or JSON) to enforce data contracts between services, ensuring consistency when handling financial transactions or other sensitive operations. Implementing schemas early avoids parsing errors and schema drift, which can be costly in production.
Kafka’s real power emerges when you start tailoring its features—idempotent producers, consumer groups, or exactly-once semantics—to your system’s needs. Whether you’re processing payments or streaming market data, understanding these fundamentals is the first step toward building robust, scalable pipelines.
Happy Kafka-ing!